Disclaimer: This is a personal web page. Contents written here do not represent the position of my employer.
Thursday, January 26, 2006
Regreso al pasado: TurboC
Resulta que un amigo mío me ha pedido que le echara un pequeño cable a su novia con una práctica de Bioinformática. Lo que hacen en esta asignatura básicamente es impartir una introducción a la programación, y en concreto usan el lenguaje C. No me parece mal que usen este lenguaje pero sí me parece mal que lo usen para lo que lo usan. De hecho, esta chica me ha enseñado prácticas de otros grupos de años anteriores y, vale, son simples y tal, pero intentan ser presentables y curiosas.
Quiero decir que no parece que la asignatura se centre al estudio de algoritmia, complejidad y demás cosas teóricas sobre la programación, sino que enseña lo que se puede llegar a hacer con la programación en general. Para eso, si yo fuera profesor, no habría escogido un lenguaje de hace siglos como C, y menos en el entorno en el que lo usan: TurboC para MS-DOS.
Intenté compilar el par de prácticas que me trajo con Linux, y descubrí que en estas prácticas existía una dependencia importante: librerías de gráficos (si les podemos llamar así) del propio entorno TurboC. Encontré un port para Linux y GCC dejó de quejarse de algunas cosas, pero no todas: seguían faltándole sin definir algunos símbolos que parecían constantes, como WHITE, BLACK, SANS_SERIF, etc. Vamos, que al final me dejé de rollos, arranqué en Windows, descargué el TurboC y me puse a programar en una consola de MS-DOS. Como el editor dejaba mucho que desear, intenté usar otro editor e invocar algún comando de TurboC que compilara automáticamente, pero no hubo manera, no encontré la herramienta adecuada o los modificadores adecuados. Pero bueno, me resigné y seguí con lo que tenía.
El problema real de Ana no era que se le diera mal la programación (que tampoco era una experta) sino que no se le ocurría nada que hacer para la práctica (era un tema libre a escoger por el alumno). Después de unos minutos de inspiración, se nos ocurrieron un par de cosas y nos pusimos manos a la obra.
Empezaron a surgir historias que me recordaban mucho a mi asignatura de Fundamentos de Programación para Sistemas Operativos, como los típicos problemas inherentes a la implementación de scanf, que deja de funcionar para posteriores invocaciones si existe algún error en la recogida de datos (en concreto a la hora de hacer casts a tipos de dato entero), lo que en ocasiones puede dar lugar a bucles infinitos. Después de decidir usar gets() en lugar de scanf() empezaron a surgir problemas con el atoi() y derivados. Al final decidí hacerme mis típicas funcioncitas que convierten de caracter a número (sabiendo que un tipo char es en realidad un entero con el valor del código ASCII del caracter, es muy fácil definir esta función).
Es por esto por lo que no estoy muy de acuerdo en usar estas técnicas de programación hoy en día, y más en el ámbito que ya he comentado. Se ve la madurez de cosas actuales como C# o Java, en el que las funciones no son globales y están englobadas cada una en su namespace o package correspondiente, en las que averiguar la longitud de un vector o cadena es algo trivial (gracias a la no necesidad de la aritmética de punteros), etc. Son soluciones mucho más amigables, potentes y productivas; ahora, que si querían evitar con esto el posible intrusismo que pudiera generar esta asignatura del plan de estudios de biología sobre el mercado laboral informático, lo han conseguido.
Quiero decir que no parece que la asignatura se centre al estudio de algoritmia, complejidad y demás cosas teóricas sobre la programación, sino que enseña lo que se puede llegar a hacer con la programación en general. Para eso, si yo fuera profesor, no habría escogido un lenguaje de hace siglos como C, y menos en el entorno en el que lo usan: TurboC para MS-DOS.
Intenté compilar el par de prácticas que me trajo con Linux, y descubrí que en estas prácticas existía una dependencia importante: librerías de gráficos (si les podemos llamar así) del propio entorno TurboC. Encontré un port para Linux y GCC dejó de quejarse de algunas cosas, pero no todas: seguían faltándole sin definir algunos símbolos que parecían constantes, como WHITE, BLACK, SANS_SERIF, etc. Vamos, que al final me dejé de rollos, arranqué en Windows, descargué el TurboC y me puse a programar en una consola de MS-DOS. Como el editor dejaba mucho que desear, intenté usar otro editor e invocar algún comando de TurboC que compilara automáticamente, pero no hubo manera, no encontré la herramienta adecuada o los modificadores adecuados. Pero bueno, me resigné y seguí con lo que tenía.
El problema real de Ana no era que se le diera mal la programación (que tampoco era una experta) sino que no se le ocurría nada que hacer para la práctica (era un tema libre a escoger por el alumno). Después de unos minutos de inspiración, se nos ocurrieron un par de cosas y nos pusimos manos a la obra.
Empezaron a surgir historias que me recordaban mucho a mi asignatura de Fundamentos de Programación para Sistemas Operativos, como los típicos problemas inherentes a la implementación de scanf, que deja de funcionar para posteriores invocaciones si existe algún error en la recogida de datos (en concreto a la hora de hacer casts a tipos de dato entero), lo que en ocasiones puede dar lugar a bucles infinitos. Después de decidir usar gets() en lugar de scanf() empezaron a surgir problemas con el atoi() y derivados. Al final decidí hacerme mis típicas funcioncitas que convierten de caracter a número (sabiendo que un tipo char es en realidad un entero con el valor del código ASCII del caracter, es muy fácil definir esta función).
Es por esto por lo que no estoy muy de acuerdo en usar estas técnicas de programación hoy en día, y más en el ámbito que ya he comentado. Se ve la madurez de cosas actuales como C# o Java, en el que las funciones no son globales y están englobadas cada una en su namespace o package correspondiente, en las que averiguar la longitud de un vector o cadena es algo trivial (gracias a la no necesidad de la aritmética de punteros), etc. Son soluciones mucho más amigables, potentes y productivas; ahora, que si querían evitar con esto el posible intrusismo que pudiera generar esta asignatura del plan de estudios de biología sobre el mercado laboral informático, lo han conseguido.
Labels: CSharp, General, Programacion
Wednesday, January 25, 2006
Copyfight
Pues me ha llamado la atención el término de Barrapunto: CopyFight. Y también su icono:
Sirve para denotar la típica guerra encarnizada entre los defensores del copyleft y los anquilosados, aterrados y anticuados defensores del copyright.
Un interesante comentario de BarraPunto que leí hace tiempo en el artículo "Por qué programo y no cobro", puede ser muy esclarecedor de lo que intentamos transmitir las personas que abogamos por el software libre y, en general, la cultura libre.
Aunque no estoy de acuerdo con esta forma de decir las cosas. La frase "programo y no cobro" no es aplicable a todos los profesionales que nos dedicamos al software libre, porque también se puede trabajar y vivir del software libre pero, en lugar de cobrar por licencias, se cobra por servicios.
Con los artistas ocurre algo parecido pero distinto. Ellos realizan servicios que, de entrada, no están remunerados. No hay contrato previo entre la sociedad y el artista. Son como los inversores, ya que invierten esfuerzo y dinero en algo que no saben si les reportará beneficios. Lo que no pueden hacer es exigir el pago posterior de esos servicios como si hubiera un contrato previo legal, que es lo que pretenden hacer con este sistema legal de licencias y derechos de autor ultra-restrictivos que se tiene montado. Este concepto se explica muy bien también en este comentario de Barrapunto.
PD: Apabullante esta entrada de Enrique Dans.

Sirve para denotar la típica guerra encarnizada entre los defensores del copyleft y los anquilosados, aterrados y anticuados defensores del copyright.
Un interesante comentario de BarraPunto que leí hace tiempo en el artículo "Por qué programo y no cobro", puede ser muy esclarecedor de lo que intentamos transmitir las personas que abogamos por el software libre y, en general, la cultura libre.
Aunque no estoy de acuerdo con esta forma de decir las cosas. La frase "programo y no cobro" no es aplicable a todos los profesionales que nos dedicamos al software libre, porque también se puede trabajar y vivir del software libre pero, en lugar de cobrar por licencias, se cobra por servicios.
Con los artistas ocurre algo parecido pero distinto. Ellos realizan servicios que, de entrada, no están remunerados. No hay contrato previo entre la sociedad y el artista. Son como los inversores, ya que invierten esfuerzo y dinero en algo que no saben si les reportará beneficios. Lo que no pueden hacer es exigir el pago posterior de esos servicios como si hubiera un contrato previo legal, que es lo que pretenden hacer con este sistema legal de licencias y derechos de autor ultra-restrictivos que se tiene montado. Este concepto se explica muy bien también en este comentario de Barrapunto.
PD: Apabullante esta entrada de Enrique Dans.
Labels: General, Politica, SoftwareLibre
Wednesday, January 18, 2006
Colaborando en MonoDevelop
Bueno, pues al final va a ser que también me voy a encargar oficialmente de traducir el fantástico entorno de programación MonoDevelop, además de Firefox. Ahora mismo van por la versión 0.9 y para la próxima se tienen planeadas grandes mejoras, como la nueva extensión que incorpora integración con Glade3 (de manera que podremos diseñar interfaces gráficas con Glade# fácilmente de una forma similar a como se realiza en Visual Studio con SWF). En esta próxima versión irá la actualización de la traducción al español, realizada por mí, junto con mi primer pequeño parche en el programa, lo cual no es otra simple cosa que la sustitución de todas las palabras "Combine" por "Solution", para evitar confusiones. Combine es el término que se usaba antiguamente en SharpDevelop para denominar a las "soluciones" (combinados de proyectos), la cual no ha sido acuñada ni por MonoDevelop ni por Visual Studio (y, puesto que MonoDevelop es un port de SharpDevelop, había que mantener uniformidad al menos en esta convención).
Me gustaría contribuir más en este proyecto, pero mi falta de tiempo hace que me retrase mucho en solventar mi falta de conocimientos que me impide realmente hacerlo. Tengo que leerme muchos documentos sobre la arquitectura de MonoDevelop y el modo de programar Add-ins (extensiones). Esperemos que no me demore mucho y pueda resultar en poder desarrollar algunas cosas que tengo en mente:
- Implementar las funciones "Ir a definición" y "Encontrar todas las referencias" que ya dispone Visual Studio.
- Mejorar el IntelliSense para que muestre la sobrecarga de constructores a medida que se va escribiendo la invocación al constructor, para que nos vaya indicando los tipos de datos de cada parámetro.
- Arreglar el tema de que los ficheros XSLT no se coloreen como los XML.
- Ayudar en el port de MonoDevelop a Windows.
Actualización 2-SEP-2006:
Parece que gracias a un parche de Levi Bard queda muy poco para tener a MonoDevelop en Windows. Muchas funciones de refactorización han sido implementadas ya, pero sigue sin haber intellisense para las sobrecargas ni constructores, ni coloreado de clases ni tooltips sobre espacios de nombres en las variables.
Dentro de poco el complemento (AddIn) de edición XML será mejorado y hospedado en el repositorio de MonoDevelop, lo que seguramente ayude al reconocimiento de las extensiones o tipos MIME.
Ya está listo un complemento de uso de ASP.NET que lanza el navegador para probar los desarrollos web, tiene muy buena pinta. Y está a punto de incluirse también otro complemento que permite agregar referencias web (a webservices).
El complemento de integración con las AutoTools es posible que ya permita a MonoDevelop para compilarse a sí mismo, lo que me animaría más a contribuir en él; en concreto me gustaría implementar algo como esto (filtrado de accesibilidad en el completado de código):
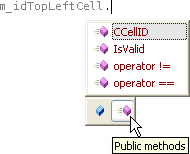
Actualización 23-NOV-2006: ¿Y qué tal si tuvieramos completado de código en el acceso a base de datos (aka MonoQuery AddIn)? Sería algo como esto:

Me gustaría contribuir más en este proyecto, pero mi falta de tiempo hace que me retrase mucho en solventar mi falta de conocimientos que me impide realmente hacerlo. Tengo que leerme muchos documentos sobre la arquitectura de MonoDevelop y el modo de programar Add-ins (extensiones). Esperemos que no me demore mucho y pueda resultar en poder desarrollar algunas cosas que tengo en mente:
- Implementar las funciones "Ir a definición" y "Encontrar todas las referencias" que ya dispone Visual Studio.
- Mejorar el IntelliSense para que muestre la sobrecarga de constructores a medida que se va escribiendo la invocación al constructor, para que nos vaya indicando los tipos de datos de cada parámetro.
- Arreglar el tema de que los ficheros XSLT no se coloreen como los XML.
- Ayudar en el port de MonoDevelop a Windows.
Actualización 2-SEP-2006:
Parece que gracias a un parche de Levi Bard queda muy poco para tener a MonoDevelop en Windows. Muchas funciones de refactorización han sido implementadas ya, pero sigue sin haber intellisense para las sobrecargas ni constructores, ni coloreado de clases ni tooltips sobre espacios de nombres en las variables.
Dentro de poco el complemento (AddIn) de edición XML será mejorado y hospedado en el repositorio de MonoDevelop, lo que seguramente ayude al reconocimiento de las extensiones o tipos MIME.
Ya está listo un complemento de uso de ASP.NET que lanza el navegador para probar los desarrollos web, tiene muy buena pinta. Y está a punto de incluirse también otro complemento que permite agregar referencias web (a webservices).
El complemento de integración con las AutoTools es posible que ya permita a MonoDevelop para compilarse a sí mismo, lo que me animaría más a contribuir en él; en concreto me gustaría implementar algo como esto (filtrado de accesibilidad en el completado de código):
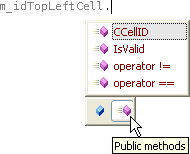
Actualización 23-NOV-2006: ¿Y qué tal si tuvieramos completado de código en el acceso a base de datos (aka MonoQuery AddIn)? Sería algo como esto:
Labels: CSharp, General, Mono, Programacion, SoftwareLibre
Tuesday, January 17, 2006
La falacia de la patria
Esta vez le toca el turno a la palabra "patria". ¿Qué significa? Pues yo no lo sé. Sinceramente creo que deberían quitarla del diccionario, o bien, poner en su lugar la siguiente cita:
"Todo por la patria": la patria, ya se sabe, el último reducto de los canallas. (Stanley Kubrick: "Senderos de gloria".)
Extraído de: Soria, retirada de símbolos.
"Todo por la patria": la patria, ya se sabe, el último reducto de los canallas. (Stanley Kubrick: "Senderos de gloria".)
Extraído de: Soria, retirada de símbolos.
Monday, January 16, 2006
Otro proyecto: DUM
¿Usas algún servicio gratuito de hospedaje de zonas DNS? Yo uso EveryDNS.net, que es gratuito, fácil de administrar, y aporta más de dos servidores DNS. Los cambios que hagas se actualizan automáticamente en los cuatro servidores.
El problema viene a la hora de utilizar IP dinámica. Yo estaba utilizando DynDNS.org (también gratuito para subdominios) para hospedar dos dominios dinámicos para dos servidores con IP's públicas que tengo escuchando en internet. Si necesitaba asociar un dominio de primer nivel (no subdominio de dyndns) a alguno de ellos, aplicaba un campo CNAME en las zonas DNS correspondientes del servicio EveryDNS.net.
Pero recientemente la gente de EveryDNS.net descubrió que esta posibilidad rompía con el estándar DNS de los RFC's que dice que si un dominio es un CNAME de otro, éste debe contener los mismos campos, exactamente igual que el otro, es decir, incluso los campos NS. Esto significa que tendría que dejar de poder utilizar dos servicios distintos para el alojamiento de DNS dinámico (DynDNS y EveryDNS.net) conjuntamente y empezar a utilizar el propio servicio de EveryDNS.net para dominio dinámico.
La ventaja que yo tenía con DynDNS es que estaba usando un paquete de software muy conocido en el mundo del software libre para estos menesteres, como intermediario entre mis equipos y el servicio DynDNS. Este software es tan maduro y conocido hasta el punto de que creo que está incluido en la mayoría de las distribuciones: ddclient, aunque hay otros muchos que cumplen la misma función. Es muy sencillo de usar, tiene soporte para muchos servicios, para muchos modos de detección de IP pública (para esta funcionalidad, soporta muchos routers, aunque yo en realidad usaba la sencilla técnica de la web de chequeo para no complicarme la vida, aunque claro, tiene el inconveniente de que se depende de un servicio de un tercero), se instala como servicio del sistema y su periodo de chequeo es configurable.
Con EveryDNS.net sin embargo no se puede utilizar ddclient, pero sí un script muy sencillo hecho en Perl que es anunciado por el propio servicio en su página. El inconveniente es que este software no es tan extensible y no tiene tantas funcionalidades. Por ejemplo, no chequea que el dominio DNS tenga la IP correcta y así no actualizar el campo de la zona (con el consiguiente ahorro de tráfico y la reducción de riesgo de que un tercero obtenga la contraseña mediante un análisis de tráfico). Además, al estar hecho en Perl, soy muy reticente a la hora de hackear el código por mí mismo, porque no tengo una devoción muy grande por este lenguaje (he pasado muchos malos ratos con él).
Por eso, decidí crear mi propia herramienta de actualización de DNS. La he llamado DUM, abreviatura de DNS Update Manager o DNS Updates with Mono, porque, efectivamente, lo he hecho en C# con Mono, claro. Esta vez he decidido probar el gestor de proyectos Novell Forge, que también tiene soporte para Subversion como Berlios.
Si alguien está interesado en probar DUM, sólo tiene que bajarse el EXE o las fuentes para probarlo. Es una herramienta de consola, que usa la librería de Mono.GetOptions (gracias Rafael Teixeira ;) y es muy fácil de utilizar.
Lamentablemente, yo no lo puedo probar aún muy extensivamente porque estoy afectado por un bug que hay en el paquete de Mono de Mandriva que aún no he tenido tiempo de tracear (investigar); y que hace que el nivel de recursos del sistema crezca de una manera desmesurada si se usa cron para lanzar DUM. Así que los beta-testers son bienvenidos.
El problema viene a la hora de utilizar IP dinámica. Yo estaba utilizando DynDNS.org (también gratuito para subdominios) para hospedar dos dominios dinámicos para dos servidores con IP's públicas que tengo escuchando en internet. Si necesitaba asociar un dominio de primer nivel (no subdominio de dyndns) a alguno de ellos, aplicaba un campo CNAME en las zonas DNS correspondientes del servicio EveryDNS.net.
Pero recientemente la gente de EveryDNS.net descubrió que esta posibilidad rompía con el estándar DNS de los RFC's que dice que si un dominio es un CNAME de otro, éste debe contener los mismos campos, exactamente igual que el otro, es decir, incluso los campos NS. Esto significa que tendría que dejar de poder utilizar dos servicios distintos para el alojamiento de DNS dinámico (DynDNS y EveryDNS.net) conjuntamente y empezar a utilizar el propio servicio de EveryDNS.net para dominio dinámico.
La ventaja que yo tenía con DynDNS es que estaba usando un paquete de software muy conocido en el mundo del software libre para estos menesteres, como intermediario entre mis equipos y el servicio DynDNS. Este software es tan maduro y conocido hasta el punto de que creo que está incluido en la mayoría de las distribuciones: ddclient, aunque hay otros muchos que cumplen la misma función. Es muy sencillo de usar, tiene soporte para muchos servicios, para muchos modos de detección de IP pública (para esta funcionalidad, soporta muchos routers, aunque yo en realidad usaba la sencilla técnica de la web de chequeo para no complicarme la vida, aunque claro, tiene el inconveniente de que se depende de un servicio de un tercero), se instala como servicio del sistema y su periodo de chequeo es configurable.
Con EveryDNS.net sin embargo no se puede utilizar ddclient, pero sí un script muy sencillo hecho en Perl que es anunciado por el propio servicio en su página. El inconveniente es que este software no es tan extensible y no tiene tantas funcionalidades. Por ejemplo, no chequea que el dominio DNS tenga la IP correcta y así no actualizar el campo de la zona (con el consiguiente ahorro de tráfico y la reducción de riesgo de que un tercero obtenga la contraseña mediante un análisis de tráfico). Además, al estar hecho en Perl, soy muy reticente a la hora de hackear el código por mí mismo, porque no tengo una devoción muy grande por este lenguaje (he pasado muchos malos ratos con él).
Por eso, decidí crear mi propia herramienta de actualización de DNS. La he llamado DUM, abreviatura de DNS Update Manager o DNS Updates with Mono, porque, efectivamente, lo he hecho en C# con Mono, claro. Esta vez he decidido probar el gestor de proyectos Novell Forge, que también tiene soporte para Subversion como Berlios.
Si alguien está interesado en probar DUM, sólo tiene que bajarse el EXE o las fuentes para probarlo. Es una herramienta de consola, que usa la librería de Mono.GetOptions (gracias Rafael Teixeira ;) y es muy fácil de utilizar.
Lamentablemente, yo no lo puedo probar aún muy extensivamente porque estoy afectado por un bug que hay en el paquete de Mono de Mandriva que aún no he tenido tiempo de tracear (investigar); y que hace que el nivel de recursos del sistema crezca de una manera desmesurada si se usa cron para lanzar DUM. Así que los beta-testers son bienvenidos.
Labels: General, Mono, Programacion, Seguridad
Sunday, January 15, 2006
Thunderbird 1.5
Bueno, pues la versión 1.5 ya salió hace unos días. La tenemos disponible en español desde la propia web de Mozilla.com, gracias al trabajo de nuestro proyecto NAVE, y gracias a que ahora la Fundación Mozilla dispone de las traducciones en su propio CVS y de esta manera los productos traducidos se generan automáticamente y al mismo tiempo que los originales en inglés.
Como consecuencia de este nuevo método de traducción, ya es menos engorroso el proceso de tener nuestros productos Mozilla traducidos a nuestro idioma. Ya no tenemos que instalar un XPI, los cuales en ocasiones dan problemas por cuestiones de permisos. El mayor ejemplo de ello es la distribución OpenSUSE/SUSE, para la que aún no se habían publicado nunca paquetes para las traducciones de Thunderbird. Ahora tenemos listos unos RPM en su FTP para estar a la última, Thunderbird 1.5 en SUSE 10.0 en nuestro idioma.
Después de instalarlos me he dado cuenta de que se incluye por omisión en el paquete la extensión OpenPGP de Enigmail. Lo malo es que viene en inglés. Seguramente esto se deberá a que las traducciones de Enigmail aún no están en el CVS (la fundación va poquito a poco...), al igual que ocurre con el Inspector DOM y demás. Pero bueno, siempre se puede seguir instalando con los XPI's de NAVE, y está bien que incluyan este tipo de cosas "de serie", para que la gente vaya trasteando con el cifrado de sus correos.
Una de las ventajas mayores que le veo a esta versión de Thunderbird es la posibilidad de borrar los adjuntos de los correos, para así ahorrar espacio en disco que de otra manera se desperdiciaría con contenido que normalmente ya hemos guardado en otro lugar. Además, al eliminar el adjunto se deja una nota de que estuvo ahí e incluso podemos dejar un enlace a la ubicación donde guardemos el fichero, con la opción "Separar".
Como consecuencia de este nuevo método de traducción, ya es menos engorroso el proceso de tener nuestros productos Mozilla traducidos a nuestro idioma. Ya no tenemos que instalar un XPI, los cuales en ocasiones dan problemas por cuestiones de permisos. El mayor ejemplo de ello es la distribución OpenSUSE/SUSE, para la que aún no se habían publicado nunca paquetes para las traducciones de Thunderbird. Ahora tenemos listos unos RPM en su FTP para estar a la última, Thunderbird 1.5 en SUSE 10.0 en nuestro idioma.
Después de instalarlos me he dado cuenta de que se incluye por omisión en el paquete la extensión OpenPGP de Enigmail. Lo malo es que viene en inglés. Seguramente esto se deberá a que las traducciones de Enigmail aún no están en el CVS (la fundación va poquito a poco...), al igual que ocurre con el Inspector DOM y demás. Pero bueno, siempre se puede seguir instalando con los XPI's de NAVE, y está bien que incluyan este tipo de cosas "de serie", para que la gente vaya trasteando con el cifrado de sus correos.
Una de las ventajas mayores que le veo a esta versión de Thunderbird es la posibilidad de borrar los adjuntos de los correos, para así ahorrar espacio en disco que de otra manera se desperdiciaría con contenido que normalmente ya hemos guardado en otro lugar. Además, al eliminar el adjunto se deja una nota de que estuvo ahí e incluso podemos dejar un enlace a la ubicación donde guardemos el fichero, con la opción "Separar".
Labels: General, Mozilla, SoftwareLibre
Tuesday, January 10, 2006
La falacia del honor
Muchos os preguntaréis, ¿qué es el honor? Pues no seré yo quien os responda porque sinceramente no lo sé. Sin embargo unos que parecen tenerlo muy claro son el ejército y algunos periodistas (como Urbaneja). Por eso voy a citar una pequeña parte de un interesante artículo de la web de informativos telecinco:
Dice Urbaneja que “cuando un general serio habla es por algo, tiene un significado que conviene atender en lo que vale”. No sabía que los generales “serios” tenían carta blanca para ir más allá de lo que la Constitución permite. Parece que algunos periodistas no se han quitado de encima la fascinación por los uniformes. Aún siguen pensando que llevar uno puesto es sinónimo de honor y sobriedad. ¿Qué habrán hecho las demás profesiones para no tener derecho a tan altas distinciones?
Dice Urbaneja que “cuando un general serio habla es por algo, tiene un significado que conviene atender en lo que vale”. No sabía que los generales “serios” tenían carta blanca para ir más allá de lo que la Constitución permite. Parece que algunos periodistas no se han quitado de encima la fascinación por los uniformes. Aún siguen pensando que llevar uno puesto es sinónimo de honor y sobriedad. ¿Qué habrán hecho las demás profesiones para no tener derecho a tan altas distinciones?
![]()

